I’ve been thinking about how generative AI impacts the ways people find, retrieve, and access information. As a technical writer, my job involves helping build systems for these purposes. This lead me to consider the ways I could build skills in this area. Inspired by Luke Hsiao’s house documentation project, I’ve been wanting to implement a document system for managing information about my house.
The thought is that bringing together these two projects, I’ll be able to create a small household-generative AI application. I’ll share my learnings and challenges along the way. And, since projects are a little more fun with cheeky names, I’m going to call this project Hinzelmann — after the figure from German folklore. Why is it cheeky? Well the Hinzelmann was a helpful figure, they were also a bit of a trickster and troublemaker.
Why use this as a case to explore generative AI?
Generative AI is a powerful UX for information retrieval. Think about how we go about finding information for a second. Let’s start with a relatively simple task: writing the regex to identify a credit card number in a text response. Regex is a great way to find patterns in strings of text, but the syntax can be difficult to parse and sometimes, for common tasks, it’s easiest to look up a pattern that already works for your case.
Let’s do a traditional websearch:
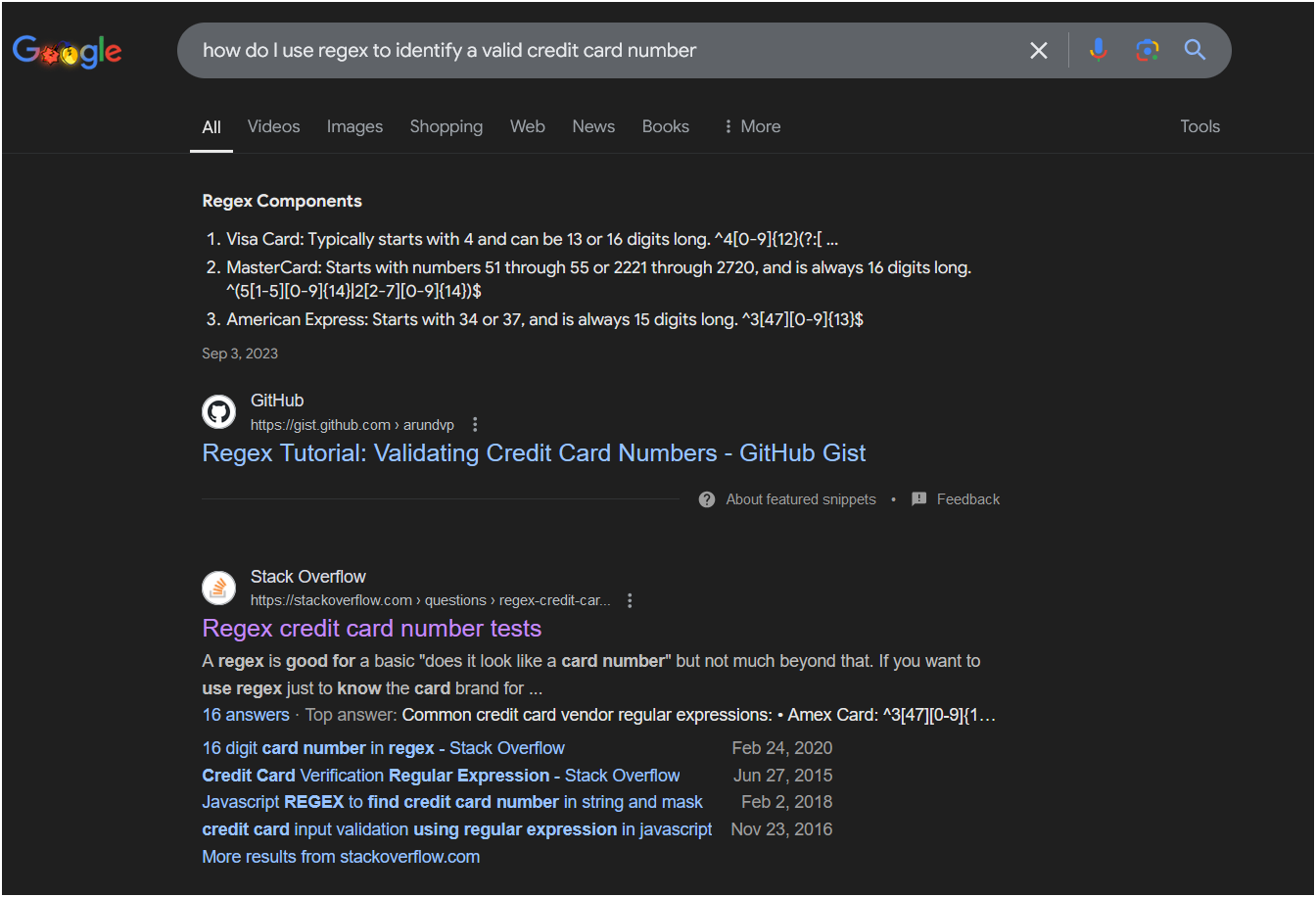
And we’ll go into stackoverflow and read a little ways down. And we have a (relatively) trustworthy answer:
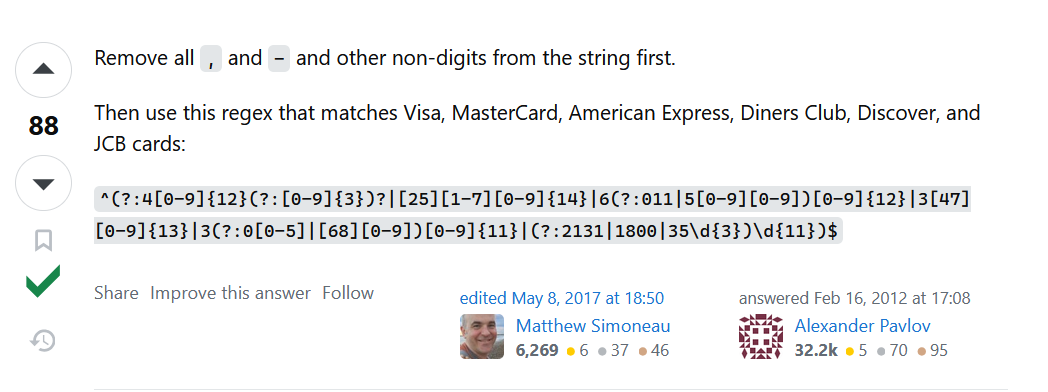
It takes effort on the part of the user to assess the linked source, parse the source information, and assess how trustworthy the information is. This is fairly cognitively complex - but it’s research skills!
While using a copilot:
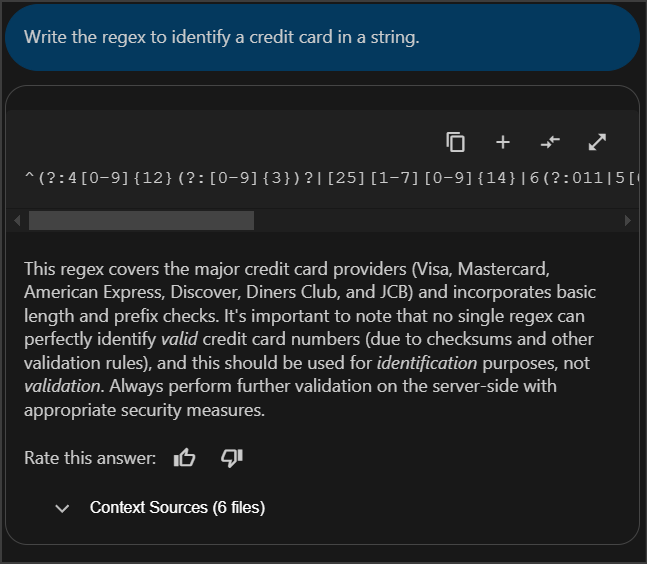
You are provided an authoritative answer without additional context cluttering the results.
Most users will understandably prefer this streamlined experience to the traditional search experience. It is fewer clicks, and much more focused as an experience. But there are some concerns you should have about this: LLMs are not search. They can behave like search — returning the most proabable sequence of responses to queries, but they have a key limitation. An LLM is trained on publicly available data up until a certain point in time. They don’t have current text patterns as part of the model.
LLMs are a poor search tool when you’re looking for new, specific, or private information: this is exactly the sort of information related to household projects, tasks, appliances, and tools. Ideally I’ll be able to use it to help plan projects, identify tasks that should be done, etc. Hopefully, I’ll be able to ask the application questions like “When did I last replace the air filter?”, “What’s the model number of our furnace?”, and so on.
RAG more carefully
One of the main architectures for trying to resolve this issue is what’s known as retrieval augmented generation. An LLM can adopt context: additional data that can be used to help shift the probability of it’s output.
The context window of an LLM depends on a number of factors — Claude’s projects have a 100mb limit for files that can be used as context. The thought is that in an LLM powered application to interact with documentation, you can query the documentation so that it can be used as particular context when providing an answer. This way the LLM has access to content that it wasn’t trained on.
Here’s the overall structure:
- Documentation is generated and maintained in a helpful and lightweight environment.
- Scripts and tools convert the documentation to a form that can be supplied to the LLM application as context.
- A user interacts with the LLM through (some kind of) interface.
- The inputs from the user are used to query the documentation.
- The query results are passed to the LLM as context.
- The output of the LLM is generated from both context and user text.
Why am I excited about this? Well, it’s a small, self-contained project about an emerging technology. I could, for example, probably skip to an effective similar result with Claude (my notes will be well within its entire context window) or existing tools for integrating note apps with ChatGPT. But this is an opportunity to explore model choice and the architecture necessary to build these kinds of applications.
I haven’t decided on what the actual build will look like yet (I’ve started research and some notes), but it’s also nice in that it puts me more in touch with the cost of running these models. For a wide range of uses, we’re obscured from seeing the costs of using these tools (both in terms of the actual expense, but also the externalities). By managing the budget and toolchain, I can be better equipped to understand the actual implications of these tools (deciding between a local LLM and an API based instance will be interesting!).
The plan
Here’s what the project looks like in terms of phases:
- Phase 1 – Content Creation: Document my house, with an eye towards notes that are well suited for this use-case.
- Phase 2 – Retrieval Tooling: Build scripts and tools to convert the content to a database that can be used with the generative AI tools of my choosing.
- Phase 3 – Back-end Implementation: Implement an application back-end to handle key tasks for handling the query and context retrieval.
- Phase 4 – Front-end Implementation: Build an interface for this so that I can interact with it without using CLI tools.
Overall the plan is to blog my way through this: I’ll create posts explaining decisions and steps that I take as I work my way through the project. How am I structuring my house documents? What decisions am I making to try and get the best result at the end? How did I decide on a model? Should I run that model locally or in the cloud?
Potential challenges
I’m excited to take this on, but it’s going to be a learning experience throughout the project. I’d consider myself ok with writing scripts and simple tools, but not a full developer by any means. In a lot of ways, this feels straight-forward: there’s nothing radically new or interesting about any part of this project, but it will be instructive to assemble these parts.
Some tool choices are going to be easy (Github, Obsidian, Python) while other parts of the project are new to me (choosing a vector database and query engine). It’s also going to require a bit of a period of dedicated work on top of regular chores — I do think the benefits will be worthwhile. Having improved notes about the house will help me with those chores and integrating them into my life, but this will take a bit more discipline on these matters.
Alternatives
This is a complicated way of doing the project, but there’s value in doing overly complicated things when you’re interested in building skills.
Here are some simple alternatives:
- Claude’s Projects allows you to store a collection of files as part of individual projects. The documentation base for your house is probably going to fall within the size window.
- You could probably achieve a similar result using Gemini Pro and Google Drive. Gemini Pro has a large context window, is a general purpose LLM, and can interact with your Google Drive content.
How to follow and contribute
You can subscribe to my blog feed for my site to receive updates on this project. I’ll be sharing code samples, documentation structure and more. And if you’d like to get in touch with me to discuss the project or have any advice, you can reach out to me through my contact page.